Linear Ridge and the Lasso can all be seen as special cases of the Elastic net In 2014 it was proven that the Elastic Net can be reduced to a linear support vector machine The loss function is strongly convex, and hence a unique minimum exists, The Elastic Net is an extension of the Lasso, it combines both L1 and L2 regularization, So we need a lambda1 for the L1 and a lambda2 for the L2, …
sklearnlinear_model,ElasticNet — scikit-learn 1,0
python
The elastic net optimization function varies for mono and multi-outputs For mono-output tasks it is: 1 / 2 * n_samples * y – Xw ,,^ 2_2 + alpha * l1_ratio * , w , _1 + 0,5 * alpha * 1 – l1_ratio * ,, w ,,^ 2_2
Regularization and Variable Selection via the Elastic Net
Fichier PDF
Elastic Net What we can do now is combine the two penalties and we get the loss function of elastic net: E l a s t i c N e t M S E = M S E y y p r e d + α 1 ∑ i = 1 m ∣ θ i ∣ + α 2 ∑ i = 1 m ∣ θ i ∣ = M S E y y p r e d + α 1 ∣ ∣ θ ∣ ∣ 1 + α 2 ∣ ∣ θ ∣ ∣ 2 2
elastic net loss function
Elastic net loss functions can also be termed the constrained type of the ordinary least squares regression loss function, The CATREG algorithm is incorporated into the elastic net, which improves the efficiency and simplicity of the resultant algorithm, In comparison, the elastic net outperforms the lasso, which outperforms the ridge regression in terms of efficiency and simplicity,
The solution is to combine the penalties of ridge regression and lasso to get the best of both worlds Elastic Net aims at minimizing the following loss function: where α is the mixing parameter between ridge α = 0 and lasso α = 1 Now, there are two parameters to tune: λ and α,
Elastic Net
Elastic Net combines the penalties of ridge and lasso to get the best of both worlds, The loss function for elastic net is The loss function for elastic net is \[L = \frac{\sum_{i = 1}^n \lefty_i – x_i^{‘} \hat\beta \right^2}{2n} + \lambda \frac{1 – \alpha}{2}\sum_{j=1}^k \hat{\beta}_j^2 + …
Elastic Net Regression Explained Step by Step
Reading through Andrew Ng’s cs229 notes he shows hereon page 10 how you can minimize a loss function $J\left \theta \right$representing the sum of least squares by taking the gradient with respect to the weight $\theta$to receive the expression $X^{T}X\theta – X^{T}\vec{y}$,
ElasticNet Regression Fundamentals and Modeling in Python
Elastic net with scaling correction βˆ enet def=1+λ 2βˆ • Keep the grouping effect and overcome the double shrinkage by the quadratic penalty • Consider Σ= XTX and Σ λ 2 =1−γΣ+ γI,γ= λ 2 1+λ 2 Σ λ 2 is a shrunken estimate for the correlation matrix of the predictors • Decomposition of the ridge operator: βˆ ridge = 1 1+ λ 2 Σ − XTy,
What are L1 L2 and Elastic Net Regularization in neural
The Need For Regularization During Model Training
7,3 Elastic Net
Elastic net regularization
Overview
Regularization: Ridge Lasso & Elastic Net Regression
python – Keras custom loss function elastic net – Stack Overflow, I’m try to code Elastic-Net, It’s look likes:And I want to use this loss function into Keras:def nn_weather_model: ip_weather = Inputshape = 30, 38, 5 x_weather = BatchNormalization, Stack Overflow,
How to Develop Elastic Net Regression Models in Python
regression
elastic_net_loss = loss + lambda * elastic_net_penalty Now that we are familiar with elastic net penalized regression let’s look at a worked example, Example of Elastic Net Regression
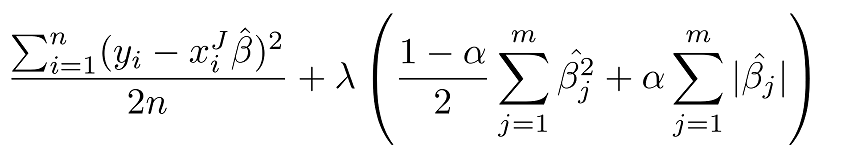
Elastic Net aims at minimizing the following loss function: ElasticNet Mathematical Model The terms used in the mathematical model are the same as in Ridge and Lasso Regression